Illuminate Predictive Models
illuminate_predictive_models is a dbt package that trains and runs predictive models directly in your data warehouse without requiring external modeling infrastructure. It supports Snowflake, Databricks, and Microsoft Fabric.
Built on top of Tuva core outputs, Illuminate Predictive Models takes a stable monthly snapshot of each member, learns from historical outcomes, and produces forward-looking predictions and evaluation metrics as standard warehouse tables your team can query immediately.
What it predicts
By default, the package is configured to predict these common targets:
- Total spend: expected paid amount per member month over the next 6 or 12 months
- Inpatient utilization: expected encounter rate over the next 12 months for
encounter_group = inpatient - Emergency department visits: expected encounter rate over the next 12 months
- SNF utilization: expected encounter rate over the next 12 months
These are defaults. You can configure any encounter-type or encounter-group based target in ml_target_policy for either paid_amount or encounter_count using target_dimension and exact target_values, validated against Tuva encounter terminology.
For encounter targets, you can also optionally predict the chance of having at least one event in the next time window. For example: "What is the probability this member has at least one emergency department visit in the next 12 months?"
For spend targets, you can also optionally predict the chance a member lands in the top 1%, 5%, or any configured k% of spend next year within their data_source.
All predictions are written as warehouse tables alongside train/test evaluation metrics so you can assess model quality before acting on results.
Why train on your own data?
Off-the-shelf risk models are typically built on standardized benchmark datasets such as Medicare FFS, a blended commercial book, or a curated research cohort. When you apply one of those models to your population, you inherit every mismatch between their data and yours: different coding practices, different payer mix, different feature fill rates, different cost distributions. Claims data is messy, and no two datasets look alike.
Training directly on your own historical data avoids these problems:
- No selection bias: the model learns from the population it will actually score, not a proxy population that may differ in age mix, geography, benefit design, or provider network.
- No feature mismatch: the model adapts to the features that are actually present and reliably populated in your data. If certain diagnosis codes or claim types are sparse in your dataset, the model learns to rely on signals that are actually there rather than assuming a fill rate it won't get.
- No cost-basis drift: allowed amounts, negotiated rates, and billing patterns vary dramatically across payers and markets. A model trained on your claims reflects your cost structure, not someone else's.
- Better calibration: because training and scoring happen on the same data pipeline, aggregate predicted totals align with actual experience. There's no "adjustment factor" needed to translate a benchmark model's output into something meaningful for your book.
Industry benchmarks from the SOA and GAO show that even the best commercial risk models explain only 10–25% of individual cost variation, and those numbers come from evaluations on the same data they were built for. Apply them to a different dataset and performance degrades further. Training on your own data is the single most effective way to maximize predictive accuracy for your specific population.
ML Model Viewer
The ML Model Viewer is a companion app for exploring predictions, evaluation metrics, and feature diagnostics from PHI-safe CSV exports. Filter by model version, data source, prediction family, horizon, and target to drill into decile distributions, train/test metrics, and feature importance.
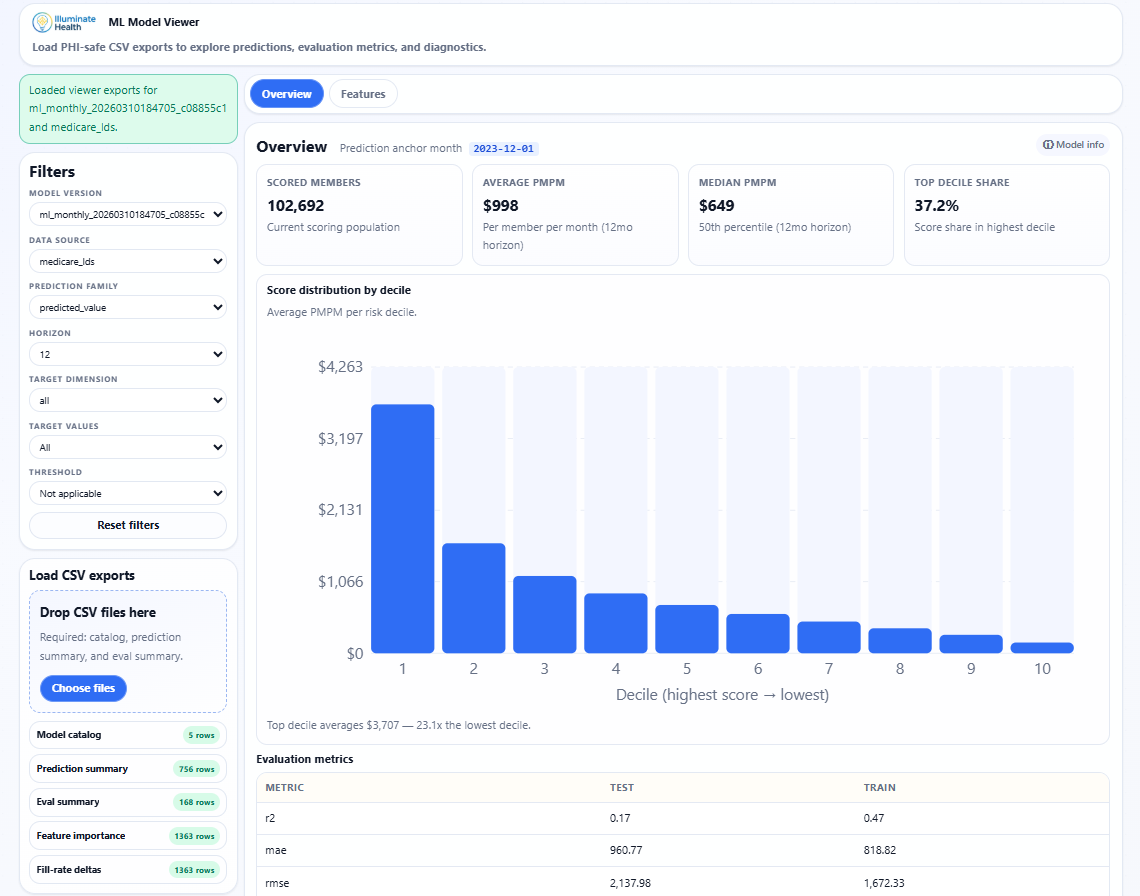
Overview tab showing scored member count, average PMPM, decile distribution, and train/test evaluation metrics.
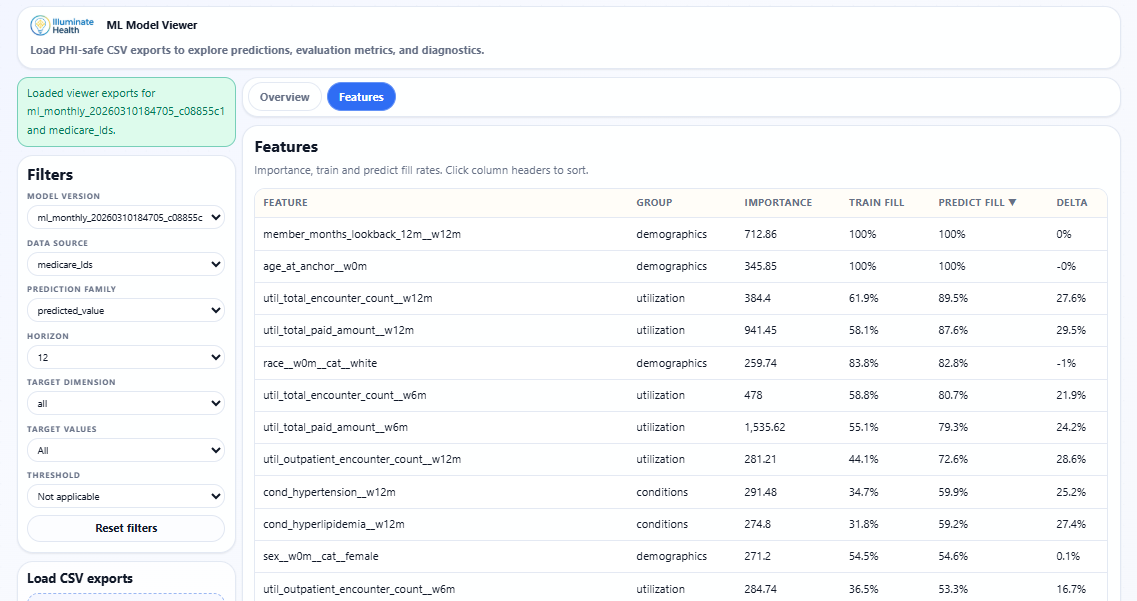
Features tab showing importance rankings, feature groups, train/predict fill rates, and fill-rate deltas.
Built for data teams
- dbt-native: fits into existing pipelines with no infrastructure changes.
- Runs in your warehouse: training and inference execute in-warehouse and support Snowflake, Databricks, and Microsoft Fabric.
- Registry-based reuse: trained model bundles are versioned, recorded in persistent history, and reused automatically to control cost and prevent unexpected drift.
- Configurable: targets, feature groups, prediction month, and training behavior are all controlled via dbt vars. No seed files, no code changes.