EMPI
A complete, warehouse-native patient identity resolution system. Includes a probabilistic matching engine, a visual configuration editor, and a manual review workbench. Everything runs inside Snowflake, Databricks, or Microsoft Fabric with nothing to host, no external services, and no PHI leaving your environment.
The matching pipeline is a dbt package (SQL + Python models). The config editor and manual review workbench are Streamlit apps deployed natively in your warehouse platform using Snowflake Streamlit or Databricks Apps. No containers, no APIs, no separate auth layer: your existing IAM, roles, and network controls apply as-is.
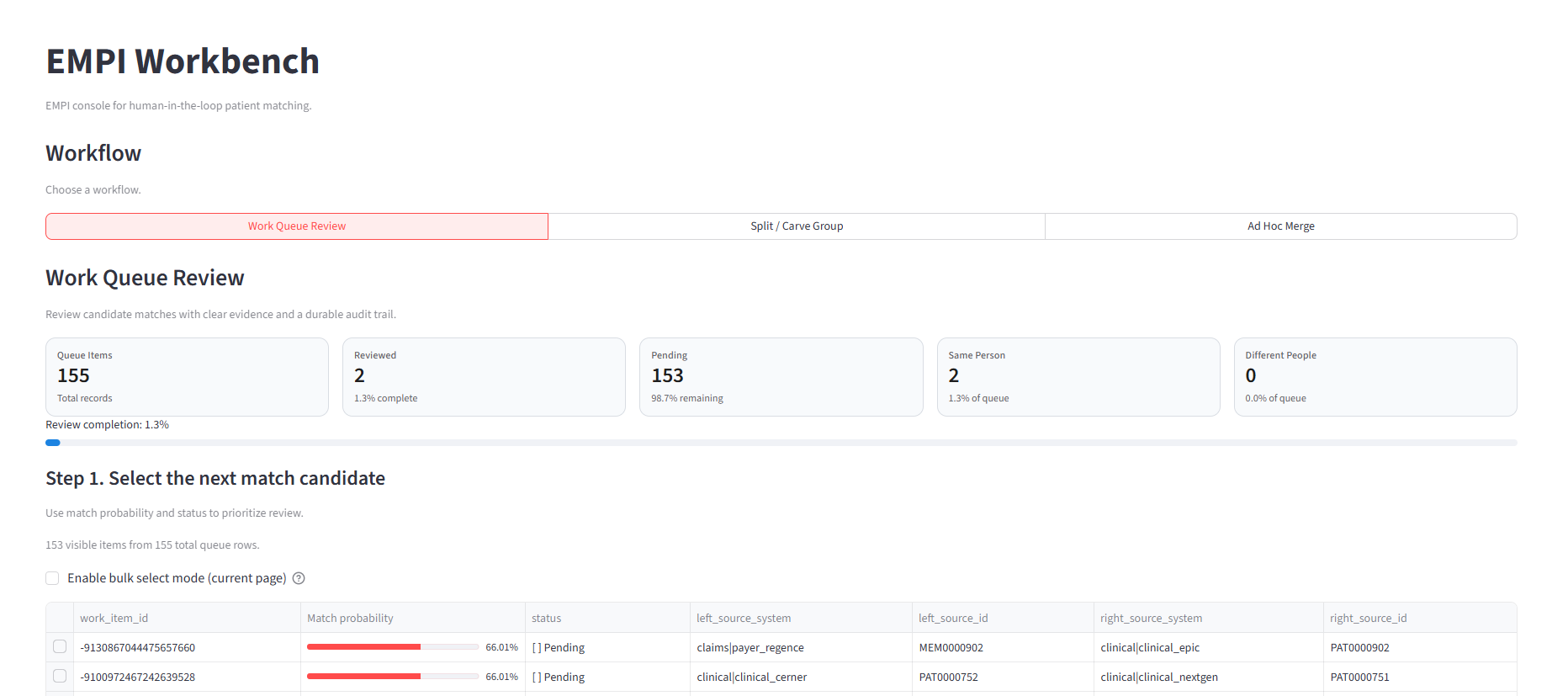
The EMPI Workbench runs as a native Streamlit app in your warehouse platform. No external hosting required.
Why this matters
Most identity resolution products are either dbt-only packages with no UI (analysts hand-edit config files and review matches in SQL) or SaaS platforms that require PHI to leave your environment. EMPI gives you both:
- Full matching engine in dbt: probabilistic linkage via Splink, survivorship, and automated remapping of downstream tables, all running as warehouse-native SQL and Python.
- Deterministic person IDs: the same configuration and input data always produce the same
person_idvalues. IDs are stable across runs, so downstream tables, dashboards, and analytics never break because of non-deterministic matching behavior. - Built-in analyst workbench: review candidate matches, split over-merged clusters, and merge missed pairs through a real UI, not a spreadsheet. Decisions feed back into the next dbt run automatically.
- Visual config editor: tune blocking rules, scoring weights, thresholds, and survivorship strategies through a browser interface with inline validation. No hand-editing CSVs.
- Zero external infrastructure: everything deploys inside your warehouse platform using native Streamlit hosting. Your existing security, networking, and access controls apply. Nothing new to provision, secure, or maintain.
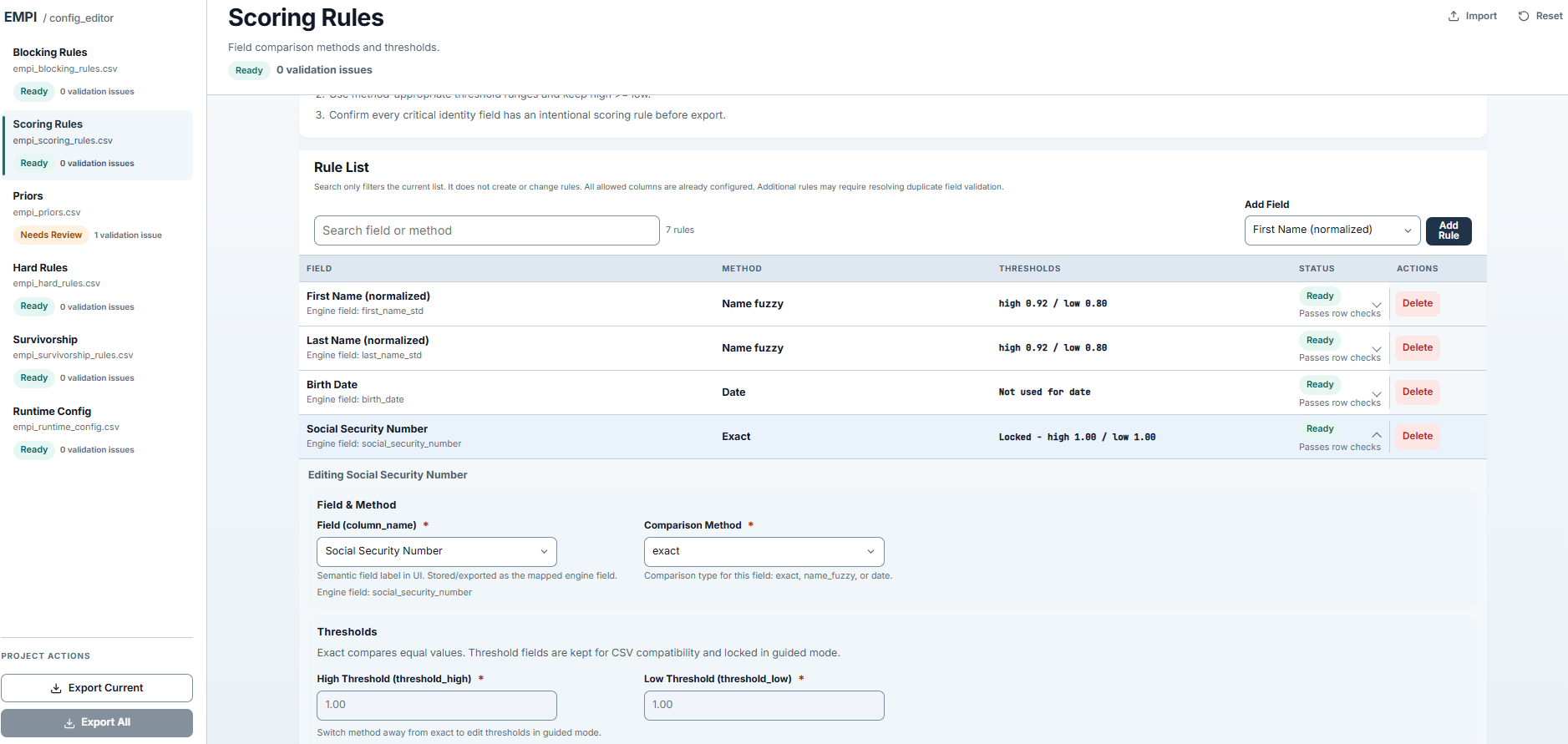
The Config Editor lets you manage scoring rules, blocking predicates, survivorship strategies, and thresholds through a visual interface, deployed natively in your warehouse.
What it does
- Standardizes demographic fields from claims enrollment and clinical patient records into a single canonical input.
- Scores candidate record pairs using Fellegi-Sunter probabilistic linkage with configurable blocking rules, comparison methods, and thresholds.
- Clusters high-confidence matches into person groups using connected-component analysis.
- Publishes a
person_crosswalk(source record → resolvedperson_id), a survivorship "golden record" (person_attrs), and a manual review work queue. - Remaps input-layer tables (eligibility, medical claims, pharmacy claims, clinical tables) with the resolved
person_idso downstream models like Tuva consume linked data automatically.
Design details
- Configuration-as-data: blocking rules, scoring comparisons, thresholds, survivorship strategies, and hard rules are managed as dbt seed CSVs, editable through the visual config editor or directly in your repo.
- Adapter-aware: the same SQL models run on both Snowflake (Snowpark) and Spark-family (PySpark) adapters. Adapter-specific Python models handle scoring and clustering, then hand off to shared SQL for everything downstream.
- Manual review loop: the package publishes a
work_queueof candidate pairs in the clerical-review band and reads back analyst decisions fromoverridesandrematch_requeststables on the next run. - Incremental: new source records trigger scoring on the next run. Existing pairs are not re-scored unless explicitly requested via rematch. Clustering rebuilds each run from current pair decisions.
Published schemas
| Schema | Purpose |
|---|---|
empi | Core linkage outputs: crosswalk, scored pairs, work queue, golden record, overrides |
core | Person dimension (core__person) |
input_layer | Remapped source tables with resolved person_id values |
Required upstream contract
Connector projects provide empi_pre__* models. Which models are required depends on enablement vars:
Claims domain (when claims_enabled: true):
empi_pre__eligibilityempi_pre__medical_claimempi_pre__pharmacy_claimempi_pre__provider_attribution(whenprovider_attribution_enabled: true)
Clinical domain (when clinical_enabled: true):
empi_pre__patientempi_pre__appointment,empi_pre__condition,empi_pre__encounterempi_pre__immunization,empi_pre__lab_result,empi_pre__medicationempi_pre__observation,empi_pre__procedure
When a domain is disabled, its corresponding empi_pre__* refs are not required.