Manual Review App
empi_manual_review_app is a Streamlit application for human-in-the-loop review of EMPI match decisions. Analysts use it to confirm or reject auto-flagged pairs, split over-merged clusters, and merge records that the scorer missed.
The app writes directly to dbt-managed overrides and rematch_requests tables, which the EMPI package reads on the next run to adjust cluster assignments.
Workflows
Work queue review
Review candidate pairs that scored in the clerical-review band (between lower_threshold and upper_threshold).
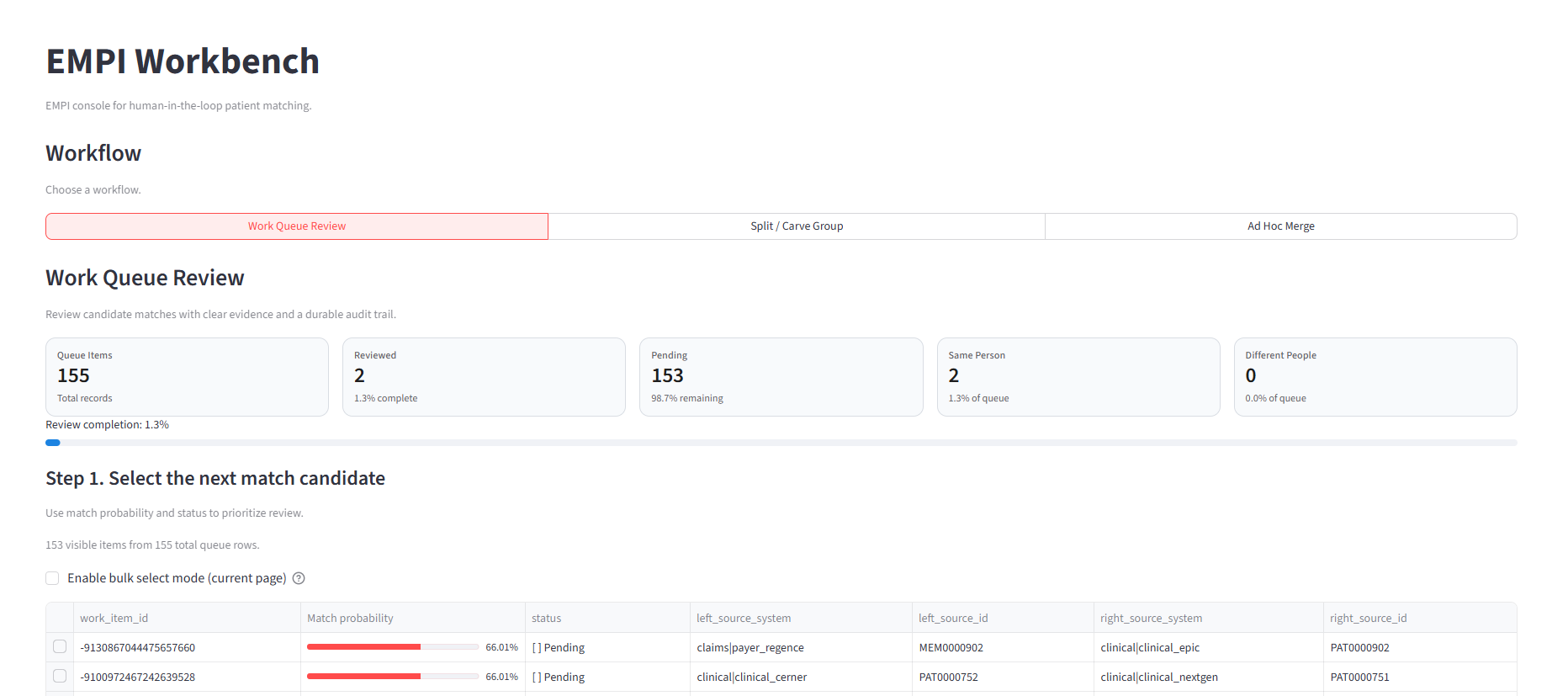
Work queue overview showing review progress, queue metrics, and candidate pairs sorted by match probability.
- Load the work queue with current override status.
- Select a pair by
work_item_idor search. - View records side-by-side with attribute comparisons grouped by: identity core, demographic, provenance, and standardized fields.
- See which blocking rules generated the pair and the match probability.
- Record a decision: Link Records (
must_link), Do Not Link (cannot_link), or skip.
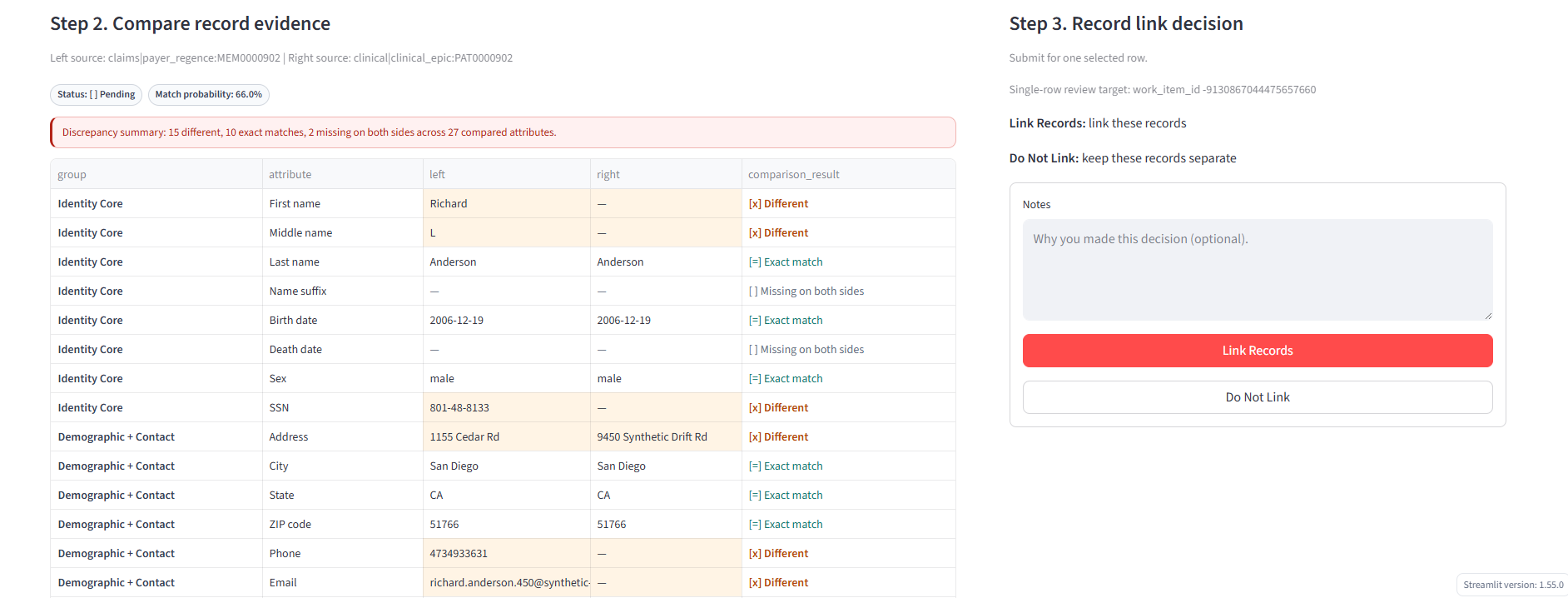
Pair review panel with side-by-side attribute comparison, match/different indicators, and link decision controls with optional notes.
Each decision is written to the overrides table with user_id, optional notes, and a timestamp. The next EMPI run applies these overrides to pair decisions before clustering.
Split / carve group
Remove specific records from an over-merged cluster so they can be re-scored independently.
- Browse person clusters by size (largest groups first).
- Select a
person_idto inspect. - View all source records in the group with their attributes.
- Multi-select records to carve out.
- Preview the impact (number of override pairs to generate).
- Confirm the split.
The app generates cannot_link overrides for every pair between carved records and remaining group members, then writes rematch_requests so the carved records are re-scored on the next run.
Ad-hoc merge
Manually link two records that the scorer didn't match.
- Search for the first record by source ID, name, email, phone, or address.
- Search for the second record independently.
- View the pair side-by-side.
- Confirm the merge.
The app writes a must_link override for the pair. The next EMPI run incorporates it into clustering.
Backend configuration
The app auto-detects the warehouse backend or accepts an explicit setting:
EMPI_SQL_BACKEND=databricks # or snowflake
Databricks
Set these as environment variables or in Streamlit secrets (st.secrets["databricks"]):
| Variable | Example |
|---|---|
DATABRICKS_HOST | adb-1234.5.azuredatabricks.net |
DATABRICKS_HTTP_PATH | /sql/1.0/warehouses/<id> |
DATABRICKS_CLIENT_ID | OAuth service principal ID |
DATABRICKS_CLIENT_SECRET | OAuth service principal secret |
DATABRICKS_CATALOG | workspace |
DATABRICKS_SCHEMA | empi |
Snowflake
| Variable | Example |
|---|---|
SNOWFLAKE_ACCOUNT | xy12345.us-east-1 |
SNOWFLAKE_USER | Username |
SNOWFLAKE_PASSWORD | Password |
SNOWFLAKE_WAREHOUSE | Warehouse name |
SNOWFLAKE_DATABASE | Database |
SNOWFLAKE_SCHEMA | empi |
SNOWFLAKE_ROLE | Role (optional) |
Required tables
The app validates these tables exist at startup:
| Table | Access |
|---|---|
work_queue | SELECT |
stg_empi_input | SELECT |
person_crosswalk | SELECT |
overrides | SELECT, INSERT |
rematch_requests | SELECT, INSERT |
Running locally
pip install -r requirements.txt
streamlit run app.py
Deployment
Databricks Apps
Deploy from a Git repo using the included app.yaml. Grant the service principal SELECT on read tables and SELECT + MODIFY on overrides and rematch_requests:
GRANT USE CATALOG ON CATALOG workspace TO `<service_principal>`;
GRANT USE SCHEMA ON SCHEMA workspace.empi TO `<service_principal>`;
GRANT SELECT ON TABLE workspace.empi.work_queue TO `<service_principal>`;
GRANT SELECT ON TABLE workspace.empi.stg_empi_input TO `<service_principal>`;
GRANT SELECT ON TABLE workspace.empi.person_crosswalk TO `<service_principal>`;
GRANT SELECT, MODIFY ON TABLE workspace.empi.overrides TO `<service_principal>`;
GRANT SELECT, MODIFY ON TABLE workspace.empi.rematch_requests TO `<service_principal>`;
Snowflake Streamlit
Deploy via Snowflake's Git-backed Streamlit integration. The environment.yml at the repo root handles dependency resolution for the Snowflake runtime.
Integration with EMPI pipeline
EMPI dbt run
→ publishes work_queue, person_crosswalk, stg_empi_input
Manual Review App
→ analyst reviews pairs, splits groups, merges records
→ writes to overrides, rematch_requests
Next EMPI dbt run
→ reads overrides → applies to pair_decisions
→ reads rematch_requests → re-scores flagged records
→ rebuilds clusters with updated decisions
Both overrides and rematch_requests are protected with full_refresh: false in dbt, so analyst work is never lost during rebuilds.